As you have already heard, one of the major features in VSAN 6.1 is the Stretched Cluster feature, with this feature Virtual SAN is enabling customers to have a 2nd site where the data exists in order to provide an increase in Availability and Data Protection, so what does the stretched cluster feature offer exactly?? Let’s take a look:
- Increased Enterprise availability and data protection
- Ability to deploy Virtual SAN across dispersed locations
- Active/Active architecture
- Syncronous replication between sites
- Site failure tolerated without data loss and almost zero downtime
So what does this mean and how does it work you may ask, well here’s the details:
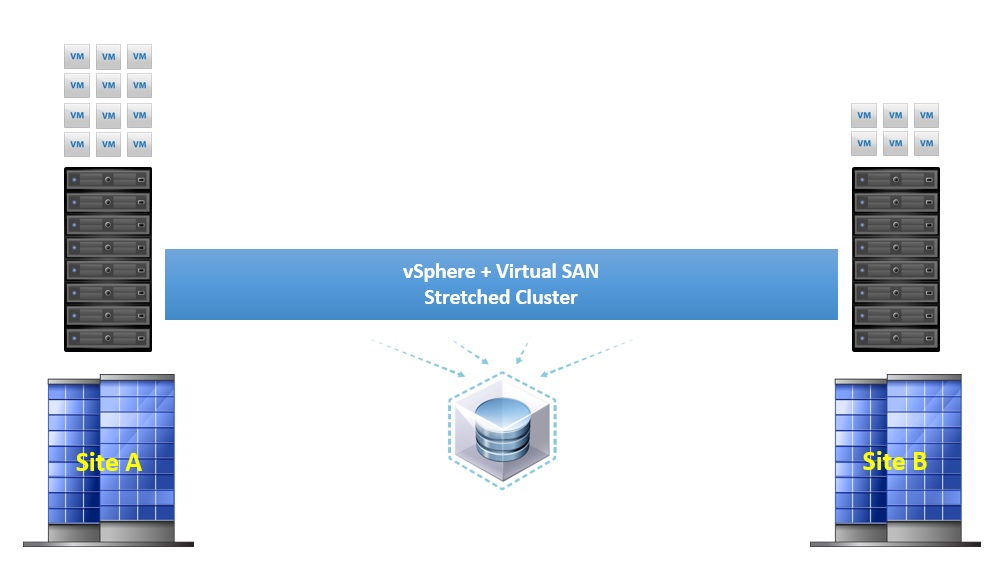
In the above scenario, we have virtual machines running on both sites so this is considered an Active/Active configuration, the Virtual SAN datastore is still a single datastore that covers both the sites as each site contributes storage to the VSAN datastore by equal capacities so in essence you have 50% of the VSAN datastore capacity on each site.
There is one question that springs to mind straight away based on the functionality of Virtual SAN….What about the Witness?.? As we know already the function of the witness is to provide >50% voting mechanism, and this is still the same in the stretched cluster, the witness still exists but this time in the form of an appliance based ESXi host which can be hosted on a third site, or even in vCloud Air.
In order to use the stretched cluster, three fault domains are required, one for each site, and a third for the witness, the below image shows this:
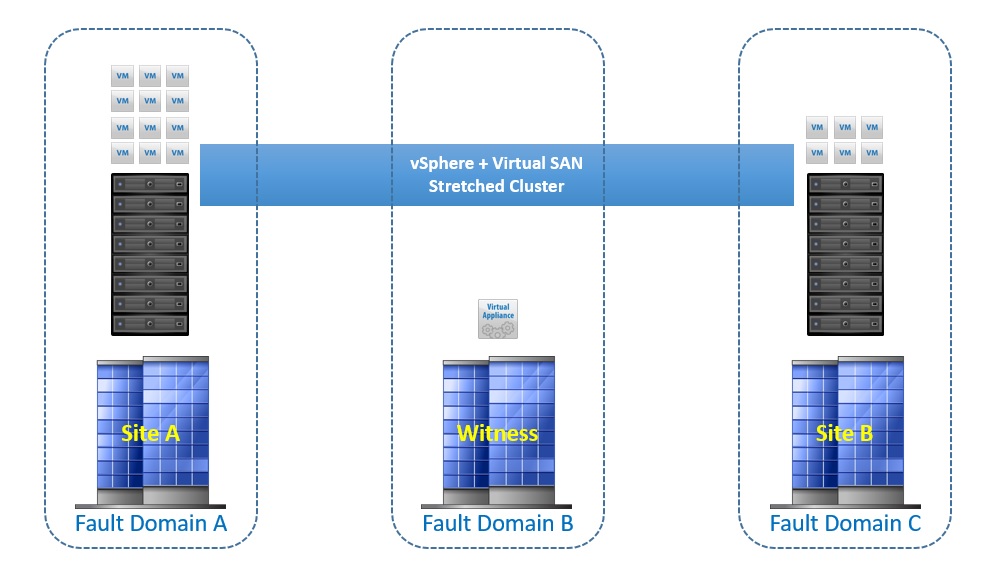
The witness only contains metadata, there is no I/O traffic from the virtual machines or VMDK data on the witness appliance, there are some space requirements for the Witness appliance though, each disk object residing on Virtual SAN needs 16Mb of storage on the witness, for example if you have 1000VMs and each VM has 4 disk objects, then the space requirement would be 4000 * 16 = 64Gb.? Each VMDK on the appliance is limited to 21000 Objects with a maximum of 45000 objects per stretched cluster.? The VMDKs for the appliance can be thin provisioned if needed in order to save space.
Another question that would be asked is what are the network requirements for the stretched cluster, the below image shows this:
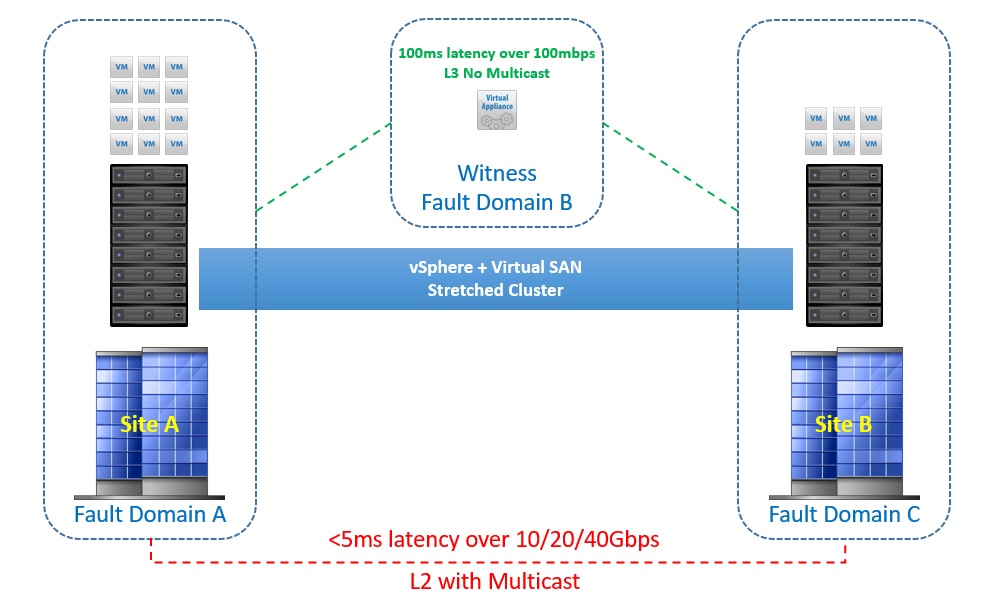
As you can see from the above image, the connection between the two sites must be at least a 10Gbps connection with latency no higher than 5ms, remember when a virtual machine submits a write, then the acknowledgement only comes when both sites have received the data with the exception of one site being down.
In addition to this, the link between the two data sites can also be routed over L3
The connection between each site and the witness site whether this be an on-premise third location or vCloud AIR needs to be at minimum a 100Mbit connection with a response time of no more than 100ms, there will be some relaxation on the response time based on the number of ESXi hosts and this would be as follows:
- Up to 10 hosts per site, latency must be below 200ms to the witness
- Above 10 hosts per site, latency must be below 100ms to the witness
The requirement of an L3 network between the main sites and the witness location, this is very important, putting them all on the same L2 network can result in I/O traffic going over the witness link which is not something you want to do
Other things to know:
Read Locality – With Virtual SAN data locality is not important, however with the stretched cluster read locality is important as it would be silly to have a virtual machine running on Site A and it fetching the reads from Site B, built into the stretched cluster functionality is the concept of read locality, the read requests will only come from the site/domain where the virtual machine compute is running, the writes will go to both sites.? If a virtual machine is vMotioned to a host in the other site, then the read locality will also switch to the site where the virtual machine compute now resides
Failures to Tolerate (FTT) – Since there are only two sites, then you can only configure storage policies with a maximum FTT=1, remember the formula for the number of fault domains required is 2n+1 where “n” is the number of FTT
Hybrid or All-Flash – Both Hybrid and All-Flash will be supported with the stretched cluster functionality
Licensing – The stretched cluster functionality will only be included in the Virtual SAN Advanced licence, this license will also cover All-Flash, so any customer who already has a license for All-Flash is automatically entitled to use the Stretched Cluster functionality